ELFSign 设计文档
0x01 项目简介
本项目名为ELFSign,已在Github开源。可对任意ELF 32/64 位文件进行签名并验证。签名后可通过readelf与objdump等工具的检测,且不影响正常运行。与本项目配套的另一工程为Kui,该项目为Linux Kernel Module,以Hook系统调用execve的方式,在ELF执行前对其进行签名校验,详细请见相关文档,该项目也已在Github开源,欢迎star。
0x02 功能介绍
ELFSign的基本功能有以下3个:
- 生成公私钥对或X509证书
- 对ELF文件进行签名,并在ELF文件中新建一个
.signsection,然后将签名储存到该section中 - 对签名后的文件进行校验,若校验通过则可执行
安装方式
该项目依赖openssl,debian类系统使用记得安装libssl相关的开发库进行编译。
git clone https://github.com/Explainaur/ELFSign
mkdir build
cd build
cmake ..
make -j8
具体的的Usage如下:
USAGE: ./ELFSign [options] file...
Options:
-c, --check Check ELF file and execute it
-X, --check-X509 Check ELF file with X509 and execute it
-s, --sign Sign a ELF file
-a, --argument Set arguments of ELF file to execute
-g, --generate Generate public and private key pair
-x, --create-X509 Generate X509 certificate
-p, --path Set the path of public/private key
-e, --elf Set the path of ELF file
Example:
./ELFSign --sign -p ./prikey.pem -e hello.out
./ELFSign -c -p ./pubkey.pem -e hello.out
./ELFSign -X -p ./ELFSign.pem -e /usr/bin/cat -a a.txt
0x03 设计原理
该项目大致可以分为一下几个模块,我会一一详细介绍各个module的原理:
- ELF文件解析模块
- ELF文件的读写Section模块
- RSA相关的签名算法模块
ELF文件解析模块
该模块主要功能为:从指定的ELF文件中加载所有的Load Segment.事实上所有对ELF读写相关的核心操作几乎都在对ELF Header与Program Header Table以及Section Header Table的解析上,我们首先来简单介绍一下ELF文件的格式。
ELF文件的宏观结构大概如下图所示:
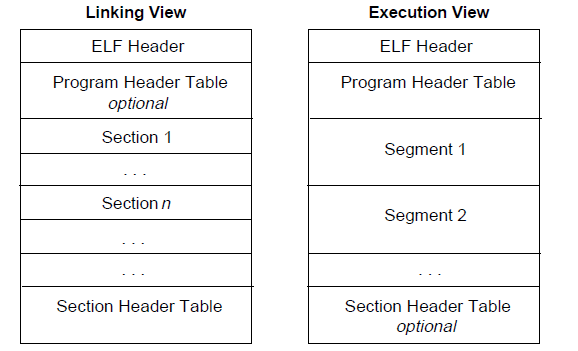
ELF文件有两种视图,一种是链接版,一种是执行版。链接版主要由section构成,运行版则主要有segment构成。那么section和segment的区别是什么? 实际上segment由section构成,在映射到虚拟内存中后,就是我们常说的data segment,code segment之类的。所以这里我们主要关心section相关的结构。
首先,我们可以看到,ELF文件由ELF Header,Program Header Table,section,Section Header Table构成。当然链接视图中,program header table是可选的,因为他主要用于告诉系统如何创建进程。用于生成进程的目标文件必须具有程序头部表,但是重定位文件不需要这个表。下面给一个比较形象的图:

可以看到Program Header Table主要和segment有关,section header table则存储了每个section相关的表项。而ELF header则存储了ELF的相关信息,比如代码段入口,section的数目,section header的offset之类的。
那么第一步,我们需要读取所有的Load Segment,上面我们已经分析了,与segment有关的信息都在Program Header Table这个struct数组里,因此我们首先应该去解析Elf32_Phdr这个结构体:
Program Header Table 是一个结构体数组,每一个元素的类型是 Elf32_Phdr,描述了一个段或者其它系统在准备程序执行时所需要的信息。其中,ELF 头中的 e_phentsize 和 e_phnum 指定了该数组每个元素的大小以及元素个数。一个目标文件的段包含一个或者多个节。程序的头部只有对于可执行文件和共享目标文件有意义。
typedef struct
{
Elf32_Word p_type; /* Segment type */
Elf32_Off p_offset; /* Segment file offset */
Elf32_Addr p_vaddr; /* Segment virtual address */
Elf32_Addr p_paddr; /* Segment physical address */
Elf32_Word p_filesz; /* Segment size in file */
Elf32_Word p_memsz; /* Segment size in memory */
Elf32_Word p_flags; /* Segment flags */
Elf32_Word p_align; /* Segment alignment */
} Elf32_Phdr;
每个字段的说明如下:
| 字段 | 说明 |
|---|---|
| p_type | 该字段为段的类型,或者表明了该结构的相关信息。 |
| p_offset | 该字段给出了从文件开始到该段开头的第一个字节的偏移。 |
| p_vaddr | 该字段给出了该段第一个字节在内存中的虚拟地址。 |
| p_paddr | 该字段仅用于物理地址寻址相关的系统中, 由于”System V” 忽略了应用程序的物理寻址,可执行文件和共享目标文件的该项内容并未被限定。 |
| p_filesz | 该字段给出了文件镜像中该段的大小,可能为 0。 |
| p_memsz | 该字段给出了内存镜像中该段的大小,可能为 0。 |
| p_flags | 该字段给出了与段相关的标记。 |
| p_align | 可加载的程序的段的 p_vaddr 以及 p_offset 的大小必须是 page 的整数倍。该成员给出了段在文件以及内存中的对齐方式。如果该值为 0 或 1 的话,表示不需要对齐。除此之外,p_align 应该是 2 的整数指数次方,并且 p_vaddr 与 p_offset 在模 p_align 的意义下,应该相等。 |
然而我们需要得出这个Segment是不是可以加载的(Loadable),因此我们需要继续分析p_type字段,细节如下:
| 名字 | 取值 | 说明 |
|---|---|---|
| PT_NULL | 0 | 表明段未使用,其结构中其他成员都是未定义的。 |
| PT_LOAD | 1 | 此类型段为一个可加载的段,大小由 p_filesz 和 p_memsz 描述。文件中的字节被映射到相应内存段开始处。如果 p_memsz 大于 p_filesz,“剩余” 的字节都要被置为 0。p_filesz 不能大于 p_memsz。可加载的段在程序头部中按照 p_vaddr 的升序排列。 |
| PT_DYNAMIC | 2 | 此类型段给出动态链接信息。 |
| PT_INTERP | 3 | 此类型段给出了一个以 NULL 结尾的字符串的位置和长度,该字符串将被当作解释器调用。这种段类型仅对可执行文件有意义(也可能出现在共享目标文件中)。此外,这种段在一个文件中最多出现一次。而且这种类型的段存在的话,它必须在所有可加载段项的前面。 |
| PT_NOTE | 4 | 此类型段给出附加信息的位置和大小。 |
| PT_SHLIB | 5 | 该段类型被保留,不过语义未指定。而且,包含这种类型的段的程序不符合 ABI 标准。 |
| PT_PHDR | 6 | 该段类型的数组元素如果存在的话,则给出了程序头部表自身的大小和位置,既包括在文件中也包括在内存中的信息。此类型的段在文件中最多出现一次。此外,只有程序头部表是程序的内存映像的一部分时,它才会出现。如果此类型段存在,则必须在所有可加载段项目的前面。 |
| PT_LOPROC~PT_HIPROC | 0x70000000 ~0x7fffffff | 此范围的类型保留给处理器专用语义。 |
这里可以看到,当p_type字段的值为PT_LOAD时,该segment是可加载的,我们也可以通过readelf -Wl ./ls这个命令来查看相关的信息,我这里截取ls的相关信息以做演示:
root@Aurora:/home/code/solo/rubbish/ELFsign/build(master⚡) # readelf -Wl ls
Elf 文件类型为 DYN (共享目标文件)
Entry point 0x6130
There are 11 program headers, starting at offset 64
程序头:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x000268 0x000268 R 0x8
INTERP 0x0002a8 0x00000000000002a8 0x00000000000002a8 0x00001c 0x00001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x003438 0x003438 R 0x1000
LOAD 0x004000 0x0000000000004000 0x0000000000004000 0x012c49 0x012c49 R E 0x1000
LOAD 0x017000 0x0000000000017000 0x0000000000017000 0x008910 0x008910 R 0x1000
LOAD 0x020390 0x0000000000021390 0x0000000000021390 0x001258 0x002548 RW 0x1000
DYNAMIC 0x020dd8 0x0000000000021dd8 0x0000000000021dd8 0x0001f0 0x0001f0 RW 0x8
NOTE 0x0002c4 0x00000000000002c4 0x00000000000002c4 0x000044 0x000044 R 0x4
GNU_EH_FRAME 0x01c12c 0x000000000001c12c 0x000000000001c12c 0x0008fc 0x0008fc R 0x4
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
GNU_RELRO 0x020390 0x0000000000021390 0x0000000000021390 0x000c70 0x000c70 R 0x1
可以看到一共有4个LOAD SEGMENT,那么接下来我们需要将对应的segment内容读出来即可,这里的方法也很简单:
p_offset字段代表该segment的偏移地址,p_filesz字段代表该segment的大小,可以对照上面的readelf的信息看,即Offset与FileSiz。- 将fd指针设置到
p_offset对应的偏移处,读取p_filesz大小的内容即可。
具体的实现大致如下,我这里读出内容之后直接就做了Hash,代码在src/elf32.c:
fseek(fd, programHeaderTable, SEEK_SET);
for (int count = 0; count < elf32->ehdr.e_phnum; ++count) {
size_t ret = fread(&tmp, 1, sizeof(Elf32_Phdr), fd);
if (ret != sizeof(Elf32_Phdr)) {
err_msg("Read Program Header failed");
return false;
}
/* Judge if Load Segment */
if (tmp.p_type != PT_LOAD || tmp.p_offset == 0)
continue;
/* Read Load Segment content */
content = GetLoadSegment32(elf32, &tmp);
SHA1_Update(&ctx, content, tmp.p_filesz);
/* Free content memory */
if (content != NULL)
free(content);
content = NULL;
}
到这里我们已经将所有的Load Segment读入并做了Hash。接下来我们就需要进行最重要的一步,完成section的添加和读写模块。
ELF文件的读写模块
该模块应当有两个功能:
- 可读任意section的内容
- 可新建一个section用来存放签名
关于section的解析,我们主要需要分析 ELF Header 与 Section Header Table。下面我们先来简单介绍一下ELF Header的信息。
ELF Header 描述了 ELF 文件的概要信息,利用这个数据结构可以索引到 ELF 文件的全部信息,数据结构如下:
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT];
ELF32_Half e_type;
ELF32_Half e_machine;
ELF32_Word e_version;
ELF32_Addr e_entry;
ELF32_Off e_phoff;
ELF32_Off e_shoff;
ELF32_Word e_flags;
ELF32_Half e_ehsize;
ELF32_Half e_phentsize;
ELF32_Half e_phnum;
ELF32_Half e_shentsize;
ELF32_Half e_shnum;
ELF32_Half e_shstrndx;
} Elf32_Ehdr;
在这里就不深入的介绍每个字段代表的详细意义,只简单介绍一些比较重要的字段。
-
e_shoff
这一项给出节头表在文件中的字节偏移( Section Header table OFFset )如果文件中没有节头表,则为 0 -
e_shentsize
这一项给出节头的字节长度(Section Header ENTry SIZE)。一个节头是节头表中的一项;节头表中所有项占据的空间大小相同。 -
e_shnum
这一项给出节头表中的项数(Section Header NUMber)。因此, e_shnum 与 e_shentsize 的乘积即为节头表的字节长度。如果文件中没有节头表,则该项值为 0。 -
e_shstrndx
这一项给出节头表中与节名字符串表相关的表项的索引值(Section Header table InDeX related with section name STRing table)。如果文件中没有节名字符串表,则该项值为SHN_UNDEF。
我们的目标是向ELF中插入一个section,那么首先要清楚ELF是怎么存储并识别section的,按照开发者的思路,我们很容易想到我们可以把每个section的信息和特征抽象成一个struct,然后把所有的struct存入一个数组,最后把数组的地址放入ELF Header就可以了。这样我们就可以直接通过ELF Header来获得section struct数组,进而间接获得section的信息。其实上面这几个字段的作用便是如此。存储struct的数组就是上面提到的Section Header Table,在ELF文件的末尾。
.shstrtab是一个字符串section,他存储了所有section的名字,ELF Header中的e_shstrndx便是其在Section Header Table中的索引,因此想要获得.shstrtab的真是偏移我们只需要按如下公式计算:
shstrtabOff = e_shoff + e_shstrndx * e_shentsize // 基址 + 索引 × 大小
那如何获得section name在.shstrtab中的具体偏移?其实section struct的真是名字叫Elf32_Shdr(32位),结构如下:
typedef struct {
ELF32_Word sh_name;
ELF32_Word sh_type;
ELF32_Word sh_flags;
ELF32_Addr sh_addr;
ELF32_Off sh_offset;
ELF32_Word sh_size;
ELF32_Word sh_link;
ELF32_Word sh_info;
ELF32_Word sh_addralign;
ELF32_Word sh_entsize;
} Elf32_Shdr;
这个结构提存储了每个section的详细信息,第一个字段sh_name是section name在.shstrtab中的偏移。
那么我们究竟要怎样才能插入一个section呢?步骤大致如下:
- 向Section Header Table中插入new section Header,即插入一个新的结构体
- 向
.shstrtabsection中插入new section的section name - 修改.shstrtab的sh_size
- 修改ELF Header中的e_shnum字段
- 向目标位置写入section内容
那么我们似乎遇到了一些困惑,.shstrtab section在ELF文件的中间,万一空间不够添加section name了该怎么办?不如我们将new section name直接添加到文件的末尾,然后修改一下sh_name不就可以了吗。 似乎想法不错,但是这里需要注意的是,我们要记得修改.shstrtab的sh_size,否则还没查到文件末尾就终止了。
修改后的ELF尾应该长这样:
|------------------------|
| section Header Table |----->这里已经插入了new section header
|------------------------|
| new section name |
|------------------------|
| section contain |
|------------------------|----> end
这里在给出一个宏观的修改厚的ELF结构图:

插入new section Header难点在计算shstrtab的偏移,首先你需要用:
offset = filesize - shstrtab.sh_offset
来获得字符串在.shstrtab中的偏移,至于怎么获得shstrtab.sh_offset.你需要先根据ELF Header中的相关字段e_shstrndx,根据这个偏移找到.shstrtab的section Header,获取对应字段就ok了。这里需要注意要将section header的其他字段设置正确。
接下来,我们需要修改.shstrtab的sh_size,用filesize - shstrtab.sh_offset就ok了,然后去修改ELF Header里的e_shnum字段,加1即可。最后向文件尾插入对应size的内容就ok了,最后我们看一下程序运行的demo:
[25] .bss NOBITS 0000000000004078 003078 000008 00 WA 0 0 1
[26] .comment PROGBITS 0000000000000000 003078 000026 01 MS 0 0 1
[27] .symtab SYMTAB 0000000000000000 0030a0 0006d8 18 28 45 8
[28] .strtab STRTAB 0000000000000000 003778 0002af 00 0 0 1
[29] .shstrtab STRTAB 0000000000000000 003a27 0008cf 00 0 0 1
[30] .sign NOTE 00000000000042f8 0042f8 000100 00 A 0 0 1
可以看到我们成功多加了一个 .sign section,再来看看文件尾:
000042f0: 2e73 6967 6e00 0000 24e4 639b 5a57 60ec .sign...$.c.ZW`.
00004300: 1aa4 e313 cb4d 3fb9 9177 0539 2551 a21d .....M?..w.9%Q..
...
000043f0: be18 7eb1 25af f246 ..~.%..F
确实符合section name + section contain的结构,看来原理是没问题的,经测试可以通过readelf和objdump的检测。
再来用objdump来验证一下看看,也没有什么问题:
root@Aurora:/home/code/solo/rubbish/ELFsign/build(master○) # objdump -h ls
ls: 文件格式 elf64-x86-64
节:
Idx Name Size VMA LMA File off Algn
0 .interp 0000001c 00000000000002a8 00000000000002a8 000002a8 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
1 .note.gnu.build-id 00000024 00000000000002c4 00000000000002c4 000002c4 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .note.ABI-tag 00000020 00000000000002e8 00000000000002e8 000002e8 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
.....
24 .data 00000268 0000000000022380 0000000000022380 00021380 2**5
CONTENTS, ALLOC, LOAD, DATA
25 .bss 000012d8 0000000000022600 0000000000022600 000215e8 2**5
ALLOC
26 .gnu_debuglink 00000034 0000000000000000 0000000000000000 000215e8 2**2
CONTENTS, READONLY
27 .sign 00000100 0000000000021eb0 0000000000021eb0 00021eb0 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
这部分代码实现在elf32/elf64.c,32位与64位的原理基本类似,这里不再赘述。
RSA签名及验证模块
这一部分相对比较简单,只是简单的封装了一下openssl的相关api,然后使用私钥签名,公钥或者X509证书进行验证。
以下代码即位签名的核心函数,具体逻辑请看下面注释,详细的源码在sign32.c
bool SignToELF32(Elf32 *elf32, RSA *pri) {
unsigned char sign[256];
/* Get Hash value of load segment */
int ret = HashText32(elf32);
if (!ret)
return false;
/* Add a new section header to Section Header Table */
ret = AddSectionHeader32(elf32);
if (!ret)
return false;
/* Add section name to .shstrtab */
ret = AddSectionName32(elf32);
if (!ret)
return false;
GetSign(elf32->digest, sign, pri);
/* Write sign to the .sign section */
FILE *fd = fopen(elf32->path, "ab+");
if (!fd) {
err_msg("Can not open file %s", elf32->path);
return false;
}
ret = fwrite(sign, 1, 256, fd);
fclose(fd);
if (ret != 256) {
err_msg("Write .text hash failed");
return false;
}
return true;
}
这里的签名即验证算法32/64位的程序原理类似,在此不再赘述。
0x04 总结
该项目的实现主要需要熟悉ELF的文件格式,实际上这种新建section的技术被广泛用于软件汉化,因为需要储存中文字符串,所以经常将汉化数据存入so文件的新的section中。我本人勉强算了解逆向工程的相关技术,所以比较熟悉ELF文件的格式。至于内核模块的Hook技术,我之前只尝试过用户态的hook,一般都是使用ptrace,这次也尝试了一下新的方法,Kui的具体原理请见其相关文档。