WHIRL相关笔记(1)
序
最近在公司做一个 RISC-V 的编译器, 要把 Open64 的全局标量优化器 WOPT 接到 LLVM 的 Codegen 模块上,让 LLVM 去做 Code Generation 的工作。WOPT的 output 是一个相当经典的 IR,叫做WHIRL。至于为啥要用 Open64,我个人认为 Open64 的循环优化和标量优化比 LLVM 激进许多,优化效果也更好。由于 Open64 的文档十分稀少,我只能边读代码边问赖师傅(逃,写这篇文章记录一下我学到的知识。
WHIRL简介
WHIRL 是树形结构,并且具有5层抽象的 Muti-Level IR,它负责粘合 Open64 各个模块。作为抽象的 IR,你可以把任何前端接到 WHIRL 上,Open64 本身支持 C/C++、Java、FORTRAN 的前端,目前我们移植了 clang 作为最新的 C/C++ 前端。多层抽象的结构让 WHIRL 保存了足够多的信息来提高优化的结果,比如 WHIRL 收集的 induct variable 和 loop condition 相关的信息可以提高循环相关的优化的效率和结果。这些信息并不像LLVM转成 Low-Level 之后从新计算得到的,此时一些信息已经丢失了,比如循环以及循环嵌套深度之类的,需要重新根据支配性和数据流去计算(Pattern Match)。而 WHIRL 是直接从 Very High Level 保留循环的相关信息,在后续的优化中会把循环 normalize 到 Do-While 的形式,并持续补全必要的数据,最终传递到 Loop-Nest Optimezer(LNO) 中进行优化。
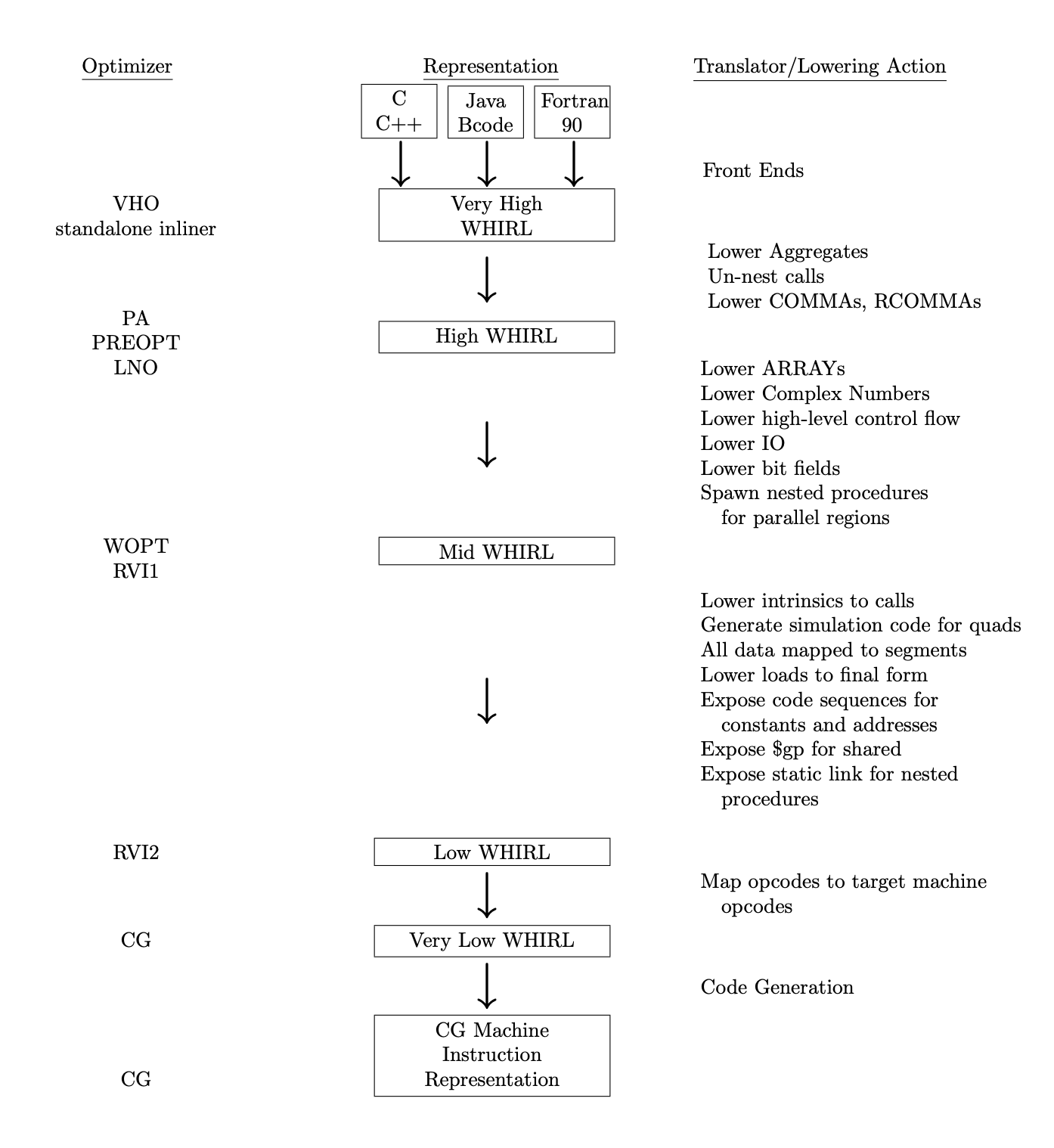
一提到 IR 大家脑子里第一个反应估计就是三地址码 (Three address code) 或者 LLVM 那种 SSA 的形式。实际上有各种各样的 IR,线形的、树形的、图形的(Eg. sea-of-nodes)等等。上文提到 WHIRL 是树形的,下图是个简单的例子:
int add(int a, int b) {
return a + b;
}
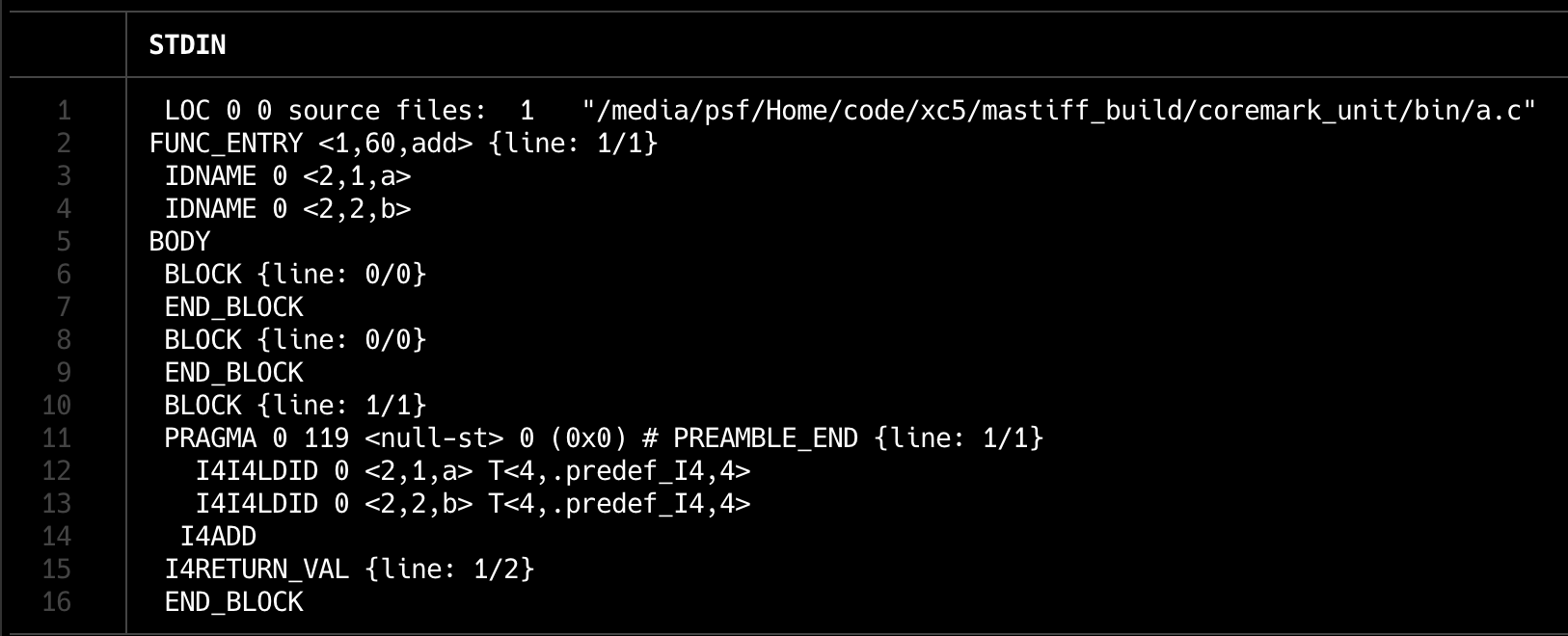
比较关键的点就是:
I4I4LDID 0 <2,1,a> T<4,.predef_I4,4> |=== Level 2
I4I4LDID 0 <2,2,b> T<4,.predef_I4,4> |=== Level 2
I4ADD |=== Level 1
I4RETURN_VAL {line: 1/2} <=== Level 0
可能大家对树形的 IR 见的并不多,我第一次见到树形的 IR 是在虎书里,树形 (tree-based) IR 和 抽象语法树 (AST) 非常接近,稍微修饰或者调整一下就可以从 AST 发射到 树形 IR,因此树形 IR 的一个好处就是可以方便的表示高级的或者抽象的结构,例如循环,分支等。你甚至可以将其无损的转换回 AST结构或者源代码,Very High WHIRL可以转换回 FORTRAN。随着编译优化的逐步进行,IR 将一步步的 Lowing 到更加底层的形式,例如将分支循环转换成 GOTO 语句和基本块的形式。当然树形 IR 并不太适合做数据流分析,在Open64 中 WHIRL 主要用来做粘合剂,标量优化 (Scalar Optimization) 主要在 SSA 上进行,循环相关的优化可以在 WHIRL 上做。
WHIRL的构成
IR 通常有三部分组成,控制流 (Control Flow)、指令和符号表 (Symbol Table)。WHIRL 也不例外,指令会被结构化的控制流包装起来,存放在程序单元(Program Units)中,类似于 LLVM Module 的概念。
int f(int a, short b) {
if (a > 0) {
return a + b;
} else {
return a * b;
}
}
该函数对应的 WHIRL:
FUNC_ENTRY <1,60,f> {line: 1/1}
IDNAME 0 <2,1,a>
IDNAME 0 <2,2,b>
BODY
BLOCK {line: 1/1}
IF {line: 1/2}
I4I4LDID 0 <2,1,a> T<4,.predef_I4,4>
I4INTCONST 0 (0x0)
I4I4GT
THEN
BLOCK {line: 0/0}
I4I4LDID 0 <2,1,a> T<4,.predef_I4,4>
I4I2LDID 0 <2,2,b> T<3,.predef_I2,2>
I4ADD
I4RETURN_VAL {line: 1/3}
END_BLOCK
ELSE
BLOCK {line: 0/0}
I4I4LDID 0 <2,1,a> T<4,.predef_I4,4>
I4I2LDID 0 <2,2,b> T<3,.predef_I2,2>
I4MPY
I4RETURN_VAL {line: 1/5}
END_BLOCK
END_IF
RETURN {line: 1/7}
END_BLOCK
里面的 IF 和 ELSE 就是控制流相关的结构,。
Instruction
首先我们介绍指令,指令在代码中被实现为 WN 结构体。指令一共分为两种:Statement 和 Expression,Statement 是指可能有副作用 (Side effects) 的指令,例如 CALL 和 ISTORE,Expression 则是指没有副作用的语句,例如 ADD, ILOAD 等运算指令。副作用可以简单的理解为不会修改程序的内存。
整个程序就是由 stmt 和 expr 构成一个树的结构,值得注意的是 stmt 的后代只能是 expr,同时 stmt 不可以是 expr 的后代 (在 VH WHIRL 中有例外),例:
I4I4LDID 0 <2,1,a> T<4,.predef_I4,4> |=== EXPR: LDID
I4STID 0 <2,3,c> T<4,.predef_I4,4> {line: 1/2} <=== STMT: STID
| |-------| |
| | |
operator operands High Level Type
一条指令由操作符(Operator)、返回类型(rtype) 和描述符类型(desc) 组成。操作符就是每条指令前面说明这条指令是做什么的,例如 ADD。返回类型指的是这条指令返回值的类型,描述符类型指的是操作数 (Operands) 的类型。例如 I4I2LDID 0 <2,2,b> T<3,.predef_I2,2> 的返回类型就是 I2,指两个字节的有符号整数,描述符类型则是 I4,指四个字节的有符号整数。
这里的I4实际上是个指针类型,WHIRL中指针和Int不做区分
以上三个属性就限定一条 WHIRL Instruction。
Data Types
WHIRL 支持一下这些类型:
| Name | Description |
|---|---|
| B | boolean |
| I1 | 8-bit signed integer |
| I2 | 16-bit signed intege |
| I4 | 32-bit signed intege |
| I8 | 64-bit signed intege |
| U1 | 8-bit unsigned integer |
| U2 | 16-bit unsigned integer |
| U4 | 32-bit unsigned integer |
| U8 | 64-bit unsigned intege |
| A4 | 32-bit address (behaves as unsigned) |
| A8 | 64-bit address (behaves as unsigned) |
| F4 | 32-bit IEEE floating point |
| F8 | 64-bit IEEE floating point |
| F10 | 80-bit IEEE floating point |
| F16 | 128-bit IEEE floating point |
| FQ | 128-bit SGI floating point |
| C4 | 32-bit complex (64 bits total) |
| C8 | 64-bit complex (128 bits total) |
| CQ | 128-bit complex (256 bits total). |
| V | Void |
| M | Struct and Array |
| BS | bits |
以上类型被称为 Machine type(Mtype),机器可以很容易表示的类型,一般写在指令的最前面,如 I4ADD。而我们注意到指令中还有 T<3,.predef_I2,2> 这样的类型描述,这个T开头的类型则指出了指令的 High-Level 的类型,比如 struct,array 等,并且 High-Level 的类型会被存放在 WHIRL 的符号表中。
例如,以下 struct 在符号表中的表示:
typedef struct list_data_s {
short data16;
short idx;
} list_data;

Kids Pointer
对于所有非叶子节点的指令,都有一个指其 kids 也就是其 Operands 的指针数组,对于能够确定 kids 数量的指令 kid_count 会指出它有都少操作数,对于 BLOCK 这种子节点数量不知道的指令,其使用 first 和 last 指针来维护一个双向链表。
Instruction Layout
如上文提到,每条 Instruction 都是一个 WHIRL node,被表示成 WN 的结构体形式。WN 最小是24个字节,有两个操作数。如果超过两个操作数,则在该结构体的末端扩展内存来存放 kid pointers.
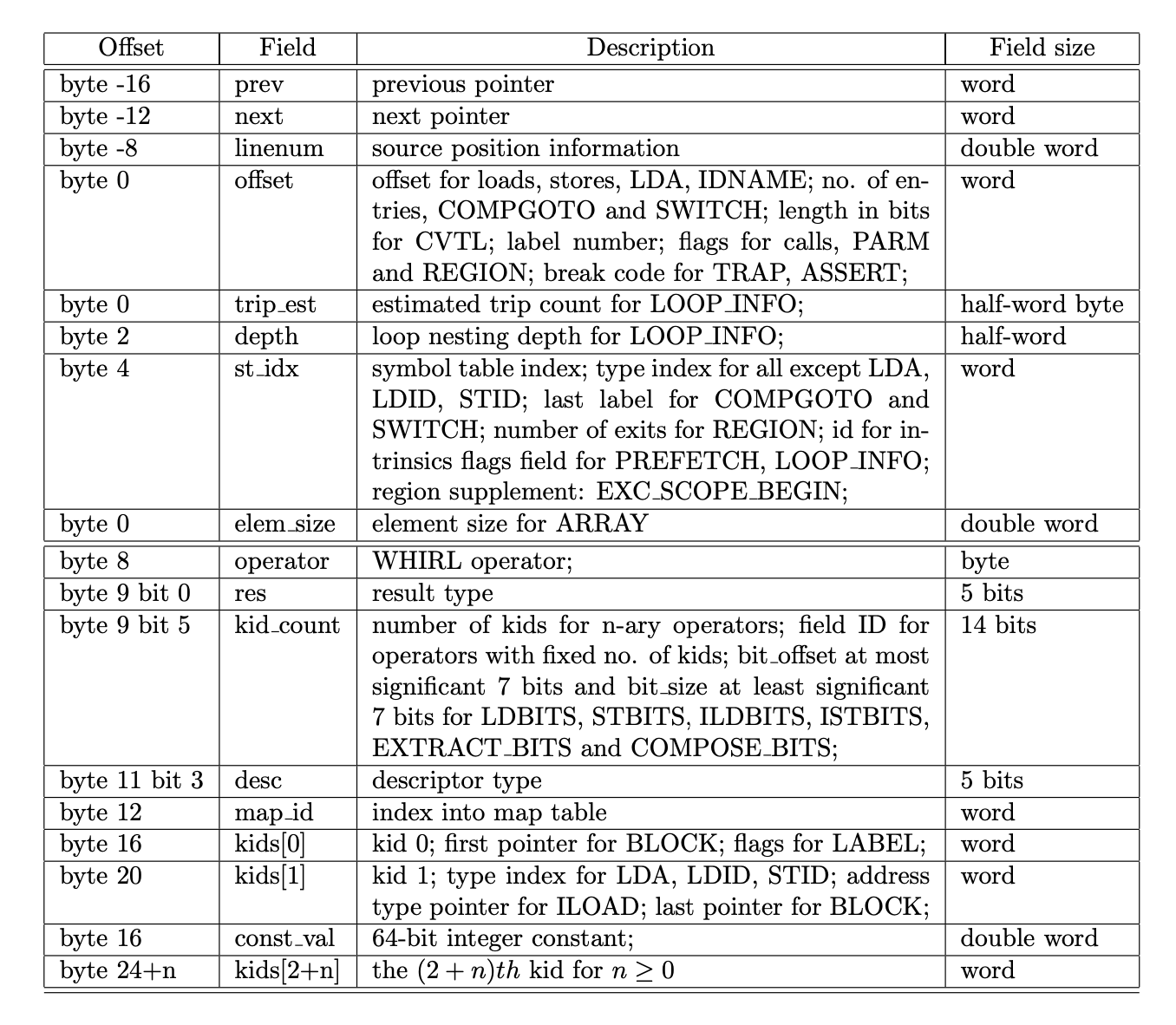
Structured Control Flow Statements
WHIRL 中的结构化控制流语句是分层的 (hierarchical),该结构中的所有 STMT 都是他的子节点。所有控制流语句的 rtype 和 desc 都是 “V”。下面来介绍各种结构化控制流语句。
- FUNC_ENTRY
- 这个操作符代表函数入口,并且该操作符是每棵树的根节点。Kids 0..n-4 是
IDNAME,代表函数的形参 - Kid n-3 和 n-2 都是是一个
BLOCK,它包含一系列PRAGMA,可以理解为c/c++中的#pragma - Kid n-1 是一个
BLOCK,它代表函数体
- 这个操作符代表函数入口,并且该操作符是每棵树的根节点。Kids 0..n-4 是
- BLOCK
- 它包含任意数量的 STMT,并且维护成双向链表的形式
- DO_LOOP
- 用于表示 FORTRAN 中的 Do-Loop
- DO_WHILE
- kid 0 是布尔表达式,代表循环条件
- kid 1 是循环体
- 循环条件将在循环体最后被测试
- WHILE_DO
- kid 0 是布尔表达式
- kid 1 是循环体
- 循环条件在最开始被测试
- IF
- 用于表示程序中的 if 语句
- kid 0 是条件表达式
- kid 1 是 then-block
- kid 2 是 else-block
DO_LOOP, DO_WHILE, WHILE_DO 和 IF只表示正常的 (well-formed) 高级控制流结构,不允许从外部直接 goto 到这些块,如果前端存在非法的控制流块,在第一个优化阶段,将筛选出此类非法的高级控制结构,并将其转换为普通控制流结构。
Other Control Flow Statements
其余的控制流语句都不是分层的。他们存在于所有level 的 WHIRL 中。
- GOTO
- 无条件跳转
- GOTO_OUTER_BLOCK
- 从嵌套过程到父过程中标签的无条件跳转。它涉及过程调用堆栈的展开。
- SWITCH
- 跟源代码中的 switch 语句很接近
- number entries 表示它跳转表的数量
- kid 0 是条件表达式
- kid 1 是他的跳转表
- kid 2 是他的 defautl block
例如:
int f(int a, int b) {
switch(a) {
case 1: return a + 2;
case 2: return b + 3;
default: return a * b;
}
}
其 switch 语句为:
SWITCH 2 258 {line: 1/3}
I4I4LDID 0 <2,3,_temp__switch_index0> T<4,.predef_I4,4>
BLOCK {line: 0/0}
CASEGOTO L514 1 {line: 1/3}
CASEGOTO L770 2 {line: 1/3}
END_BLOCK
GOTO L1026 {line: 1/6}
END_SWITCH
- CASEGOTO
- 只存在于 SWITCH 中,用于表示条件跳转
CASEGOTO L514 1表示 cond 为1就跳到 L514
- COMPGOTO
- 和 SWITCH 很类似,唯一的区别是他的 case 永远从 0 开始,因此它的
BLOCK中只有GOTO - 该语句通常出现在 M/L WHIRL 中,即 SWITCH 被优化过的结果
- 和 SWITCH 很类似,唯一的区别是他的 case 永远从 0 开始,因此它的
- TRUEBR
- 条件跳转指令
- kid 0 是条件表达式,为 true 则跳转至对应的 BLOCK,常用见 IF 语句被优化之后的结果
- FALSEBR
- 和 TRUEBR 类似
- kid 0 是条件表达式,为 false 则跳转至对应的 BLOCK,常用见 IF 语句被优化之后的结果
- RETURN
- 无返回值的 return
- RETURN_VAL
- kid 0 是其返回值
- LABEL
- 代表一个基本块的开始,和 C/C++ 里的 label 一样
- LOOP_INFO
- 不是一个STMT,用于储存循环相关的信息