WHIRL相关笔记(2)
序
上次我们大致介绍了Open64的WHIRL指令的基本设计和结构,文本讲简单介绍一下WHIRL的符号表设计。符号表 (Symbol Table) 是编译器中的一个重要模块,记录了源代码的一些重要信息。课本中介绍的符号表是比较狭义的、货真价实的“符号”表。这种狭义的表结构用于存放源代码中的各种符号,例如变量,函数的一些重要信息,比如类型信息,初始化值等等。并且该结构需要能够区分不同作用域中的同名符号,例如:
int f(int a) { // parameter a in the scope s0
if (a > 0) {
char a = 1; // variable a in the scope s1
int b = 2; // variable b in the scope s1
return b;
} else {
int16_t b = 3; // variable b in the scope s2
return b;
}
}
两个名为“b”的变量出现在了不同的作用域,应当在符号表中予以区分。然而真实的工业编译器的符号表通常保存了更多详细的程序信息,用于后续的IR生成、检查以及优化。
Trivial Symbol Table
在介绍WHIRL这个庞然大物的复杂符号表之前,我们先来介绍一下一种非常简单的符号表的设计,通常用于玩具编译器的实现。以C语言为例,不考虑struct/union这种复杂语法,下意识里我们很快的能想象出一种合适的数据结构来实现符号表,那就是哈希表。可以使用符号名作为哈希表的键,用SymInfo这个struct作为哈希表的值,来保存符号的类型等信息。以序中的函数f为例,scope s1的符号表可以长下面这样:
| Name | SymInfo::Type | SymInfo::Init | SymInfo::IsConst |
|---|---|---|---|
| a | CHAR | 1 | false |
| b | INT | 2 | false |
我们可以把程序的scope当作一个树进行处理,因为这里我们需要解决三个问题:
- 对于C语言而言sub scope中的符号可以遮盖super scope中的符号,例如上述代码中scope s1中的char a变量会覆盖,scope s0 中的 int a 参数。
- super scope无法访问sub scope中定义的符号,sub scope却可以自由访问super scope。
- 同级scope中的符号是互相屏蔽的,例如在scope s2中看不到scope s1中定义的a,b两个符号。 因此,我们需要设计一种可以满足上述要求的简单数据结构。对于一个玩具编译器而言,做完语意分析,确保没什么类型错误,并且后面发射IR用不到的话,就可以把符号表丢掉了。这里可以使用嵌套哈希表(Nested Hash Map)进行实现,如下图:
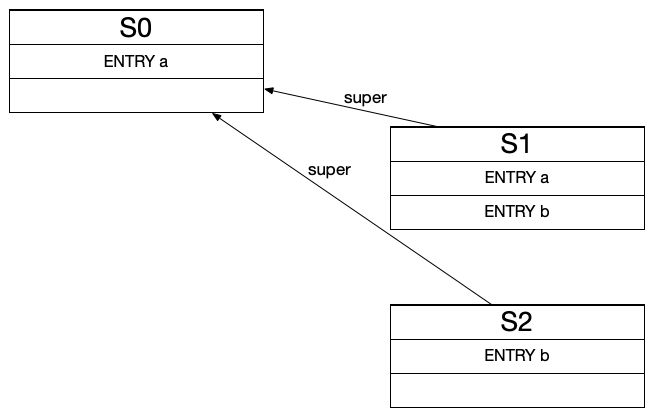
如图所示,S0、S1、S2均维护一个哈希表结构,同时维护一个Super Scope的指针信息,当然S0的Super Scope是NULL。用代码实现大概如下:
class SymTreeNode {
unordered_map<string, SymInfo *> symbols;
SymTreeNode *super;
public:
SymInfo *GetSymInfo(const string &name, bool recursive) {
if (symbols.find(name) != symbols.end()) return symbols[name];
if (recursive) {
return super->GetSymInfo(name, true);
}
return nullptr;
}
void AddSymInfo(const string &name, SymInfo *info) {
symbols[name] = info;
}
// more methods ...
};
通过这种简单的数据结构,我们可以解决上述提出的三个问题,每个SymTreeNode代表一个scope,每个节点只能递归的访问super scope,并且不能访问。当通过访问者模式遍历语法树进行语意分析时,可以边访问树节点,边构建或查询符号表。
这种简单的结构处理一下C语言没什么问题,但是设计上仍然有很多问题,首先无法自顶向下的访问整个符号表,由于设计只考虑了scope的特点,只能自底向上的访问符号表,其次,无法通过随机访问的方式获得符号表项,并且符号表保存的信息不够丰富等等。总的来说,这个结构的使用效率不高,信息粒度也不够细。提出这个结构只是为了更详细的解释一下符号表的功能,接下来让我们把视线转到WHIRL的符号表。
WHIRL Symbol Table
WHIRL符号表不像上述设计只有一个表结构,它包含了一系列表格用于编译、优化并且保证运行于存储的效率。从宏观上看,WHIRL的符号表被分成了全局(Global Part)和本地(Local Part)两部分,如下图所示:
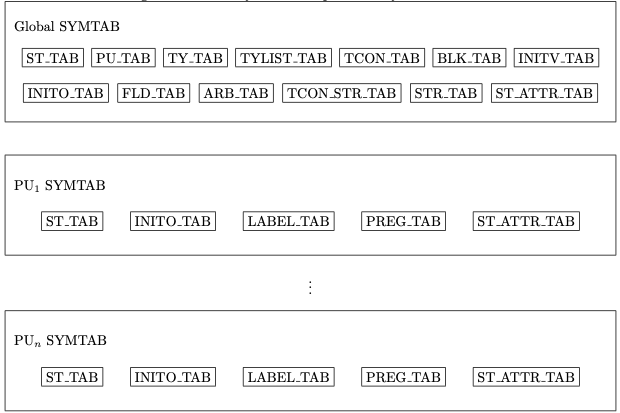
可以看到Global SYMTAB保存了许多用于全局访问的信息,例如用于存储类型信息TY_TAB和存储函数信息的PU_TAB等等。每个函数(Program Unit)自己也维护一个本地的符号表,其中包含了更多的详细局部信息,比如保存了伪寄存器信息的PREG_TAB等等。
可以看出WHIRL Symbol Table的本地表并不是树形结构,只有几个独立的线性表,这种设计可以提高符号表的读写速度。
我们接下来介绍各个表的大概功能和结构:
ST_TAB
这个表有点类似于上面提到的狭义的符号表,也是整个符号表中最重要的模块之一,任何有名字的符号(变量、函数、伪寄存器)都被包括在这个表中。每一个表项 (ST Entry) 都有一个独一无二的索引ST_IDX。
事实上后续介绍的各个表都会给其表项提供一个独一无二的索引例如 TY_TAB 表的 TY_IDX,用于实现表项的随机访问,后续不再赘述。
ST Entry包含了对应符号的详细信息,例如名称、属性、type、符号类型、存储类型等等,其结构如下:
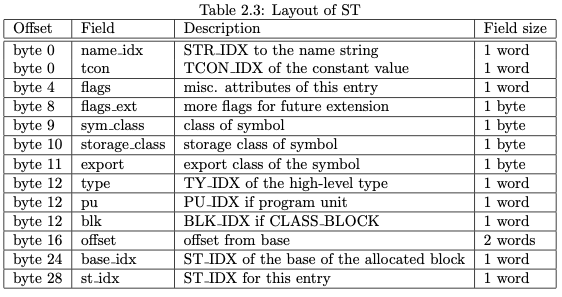
根据上述信息我们可以发现,即使是函数中有多个重名变量也为所谓,因为访问符号表并不是通过符号名或者其哈希值作为访问的key,而是通过唯一的ST_IDX或者ST Entry指针进行访问,符号名仅作为一个信息存储起来。该结构体中的表项不再详细介绍,看名字和描述基本上可以推断出相关信息。值得注意的是,ST表的索引也会被对应的WHIRL指令所保存,用于记录该指令的符号信息。我们通过一个简单的程序举个例子:
const int a[] = {0};
int main() {
int b = 3;
return a[0] + b;
}
该程序的局部符号表中变量b对应的Entry如下:
=======================================================================
SYMTAB for main: level 2, st 9, label 0, preg 0, inito 0, st_attr 0
=======================================================================
Symbols:
[1]: b <2,1> Variable of type .predef_I4 (#4, I4)
Address: 0(b<2,1>) Alignment: 4 bytes
location: file (null), line 3
Flags: 0x00000000 Flags_ext: 0x02200000 modified used, XLOCAL
SYMTAB的level用于区分是全局表还是本地表,可以看到main的level为2,是本地表,全局表的level应当为1。其中b <2,1> 2是level,保存在ST_IDX的低8位中,1则是在当前表中的index,这里的index是ST_IDX的高24bits。紧随其后的是当前符号的类型信息,可以看到变量b的类型为int类型,在WHIRL中表示为 .predef_I4, 代表预定义的基本类型。这里类型 TY 与上一篇文章介绍的 MTYPE 有所不同,MTYPE用于表示机器类型,即寄存器或者CPU能处理底层类型。而这里的TY则是高级的,保留了前端语意信息的类型,例如struct或者class等等,应当与MTYPE作区分。
PU_TAB
PU是Procedure Unit的缩写,在WHIRL中代表函数。PU_TABLE则保存了当前文件中所有的函数原型(Prototype)和函数声明(Declaration),PU Entry的结构大致如下图:

由于Open64后来进行了一系列更新,该结构体新增加了一个比较重要的成员 TY_IDX base_class,当该函数是某个struct/class的成员函数时,base_class 记录其owner的类型。
TY_TAB
该表记录了编译器前端保留的所有high-level type,包括基本的标量类型(Scalar Type)、指针类型以及更复杂的聚合类型(Aggregate Type)。每一个TY Entry保留了对应类型的详细信息,例如类型的大小和对齐信息、对应的MTYPE、数组元素类型信息以及pointee type等等。其结构如下图:
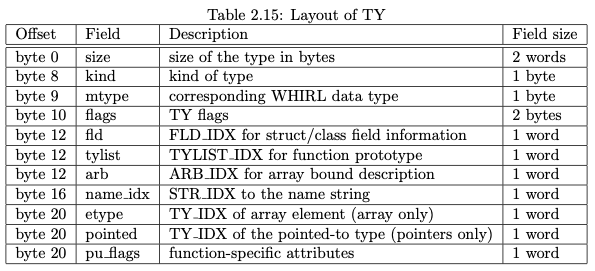
我们以如下代码为例:
struct A {
int num;
char name[100];
struct A *next;
};
该结构体对应的TY打印出的信息如下:
[66]: A : (f: 0x0000) size 112 M: STRUCT
0 num .predef_I4 (#4) align 4 fl:0x0080
4 name (anon) (#67) align 1 fl:0x0080
104 next anon_ptr. (#68) align 8 fl:0x0081 last_field
[67]: (anon) : (f: 0x0020 anonymous) size 100 M: ARRAY of .predef_I1 (#2) align 1 (0:99:0:)
[68]: anon_ptr. : (f: 0x0000) size 8 U8: -> A (#66) align 8
以上信息打印出了struct A的详细类型信息,我们以其第三个成员 next 为例,开头的104是该成员与结构体开始地址的偏移,紧随其后的是该成员的name,之后的anon_ptr. (#68)为当前成员的类型,一个匿名指针类型,该类型在TY_TABLE中的index为68,可以看出该指针的pointee type为 struct A * 类型。之后的 align 8 表示该类型8字节对齐。接下来 fl:0x0080 则记录了该成员的更多详细细节,通过16位的flag记录,本文不再详细介绍flag信息。最后last_field表示当前成员是最后一个field。
FLD_TAB
该表的每个Entry都提供了关于 struct 或 union 中的field信息。结构类型的TY指向第一个field的FLD条目。其余field紧随在连续的FLD_TAB项中,直到有一个标志表明它是最后一个field为止。FLD Entry的结构如下,大小为24字节:

其中 bsize 和 bofst 这两个成员记录了bit field的位长和偏移。bit field是C/C++里用的不太多的特性,简单来说就是可以更精确的控制field的位长,例如:
struct A {
int a : 4; // 4 bits
char b : 1; // 1 bits
};
成员a和b的位长分别为4位和1位,这种语法特性可以让程序员更加极致的使用内存,同时也增大了编译器处理结构体内存对齐的复杂度。
ARB_TAB
该表的每个Entry都提供了关于数组维数的信息。数组类型对应的TY Entry包含了第一个维度的ARB Entry指针,由ARB_FIRST_DIMEN表示。对于C/C++数组,这对应于最左边的维度。
TCON_TAB
TCON用于存储整数、浮点数或者字符串常量的值。该表的前三个条目被保留。第一个条目 (index 0) 为未初始化的索引所保留的值。第二个条目 (index 1) 包含4字节的浮点值0.0。第三个条目(index 2)包含8字节浮点值0.0。这些条目是共享的。所有其他值都是独立输入的,不检查是否重复。TCON表项的结构如下,大小为40字节:
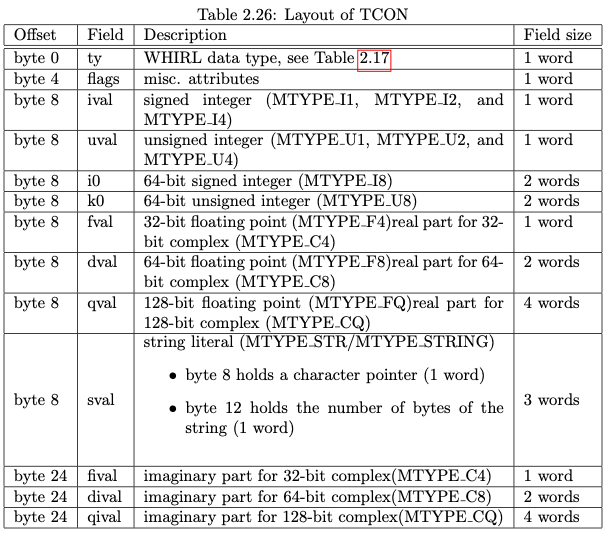
一般各种变量的初始化值都被保存为TCON。
INITO_TAB
该表的表项用于描述全局变量或者静态变量的初始化值,真实的初始化值被存储在INITV_TAB中,而INITO_TAB则维护变量与INITV Entry的映射关系。INITO Entry的结构如下图:

INITV_TAB
INITV主要记录了各种初始化值,简单的标量值由一个INITV对象进行表示,复杂数据对象的初始值由一个INITV树进行表示,其根由INITV的INITV_IDX指定,INITV条目的结构如下,大小为16字节:
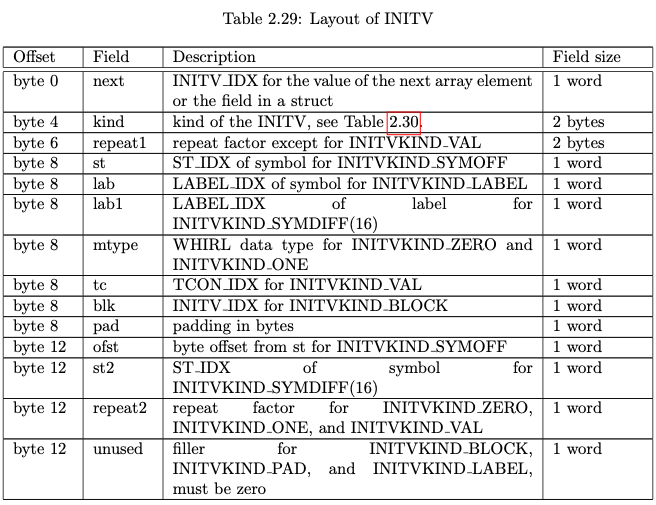
可以看到tc成员记录了初始化值的TCON_IDX,用于在TCON_TAB中获取对应的常数值。而blk成员则用于表示 struct/union 这种复杂的初始化值的聚合,其对应的子INITV节点相当于一颗子树,记录了更多复杂的初始化信息。
STR_TAB
该表保存了Symbol、types、label等名称的所有字符串。该表可以被视为字符串的存储区域块。STR_IDX是该表的索引,实际上是这个存储块中的偏移量,它给出字符串的开始字符的字节偏移量。所有字符串都以空结尾,并且块的第一个字符总是空的。因此,零STR_IDX表示空字符串。这个表的设计很像ELF文件里的 .shstrtab 或者 .strtab,都是通过偏移访问字符串的值。
总结
以上大致介绍了WHIRL Symbol Table中比较重要的几个表,还剩下几个BLK_TAB、LABEL_TAB这种比较简单的表,本文就不再详细展开。语法树和IR都非常依赖符号表的信息,但是访问符号表的方式和需要又有所区别,因此符号表的设计应当考虑到各方面的应用场景,降低算法的复杂度并且提高内存的利用效率。作者并没有深入了解LLVM符号表的相关实现,本文就不再深入对比两个符号表设计上的差异。感兴趣的朋友可以参考一下Open64新添加的WHIRL to LLVM 的原型模块 (这个模块是我写的 ^_^),能够更深入的体会到两种IR甚至是两个编译器设计上的差异。
阅读量